Threat Intelligence for Crypto Payments: Architecting Real-Time Defense Into Your Payment Stack

Crypto payment infrastructure has a security problem that most teams notice too late. You build the checkout flow, wire up the wallet signing, handle webhook retries, and then — sometime after you're in production — you discover that your hot wallet address is being probed, your RPC endpoints are being abused, or that a counterparty address you accepted funds from was flagged by three separate intelligence feeds two days before the transaction settled.
The usual response is to bolt on a compliance tool, run a one-time screen, and call it done. That's not threat intelligence. That's a checkbox.
Teams think the problem is finding the right screening vendor. The real problem is that threat intelligence for crypto payments is an architecture decision, not a product purchase. Where you insert signals into the transaction lifecycle, how you operationalize feeds at runtime, and what you do when a signal fires mid-payment — those are engineering problems that no dashboard solves for you.
This guide is about wiring threat intelligence into crypto payment infrastructure at the layer where it actually matters: before, during, and after money moves.
Table of contents
- Why threat intelligence is different in crypto
- The four threat layers every crypto payment stack faces
- Mapping threat signals to the payment lifecycle
- Choosing and integrating threat intelligence feeds
- Operationalizing signals: rules, thresholds, and automation
- Common failure modes when teams build this wrong
- What breaks under load and adversarial conditions
- Integration patterns: APIs, webhooks, and event pipelines
- Connecting proactive and reactive security work
- Product fit: where coinpayportal.com fits this architecture
Why threat intelligence is different in crypto
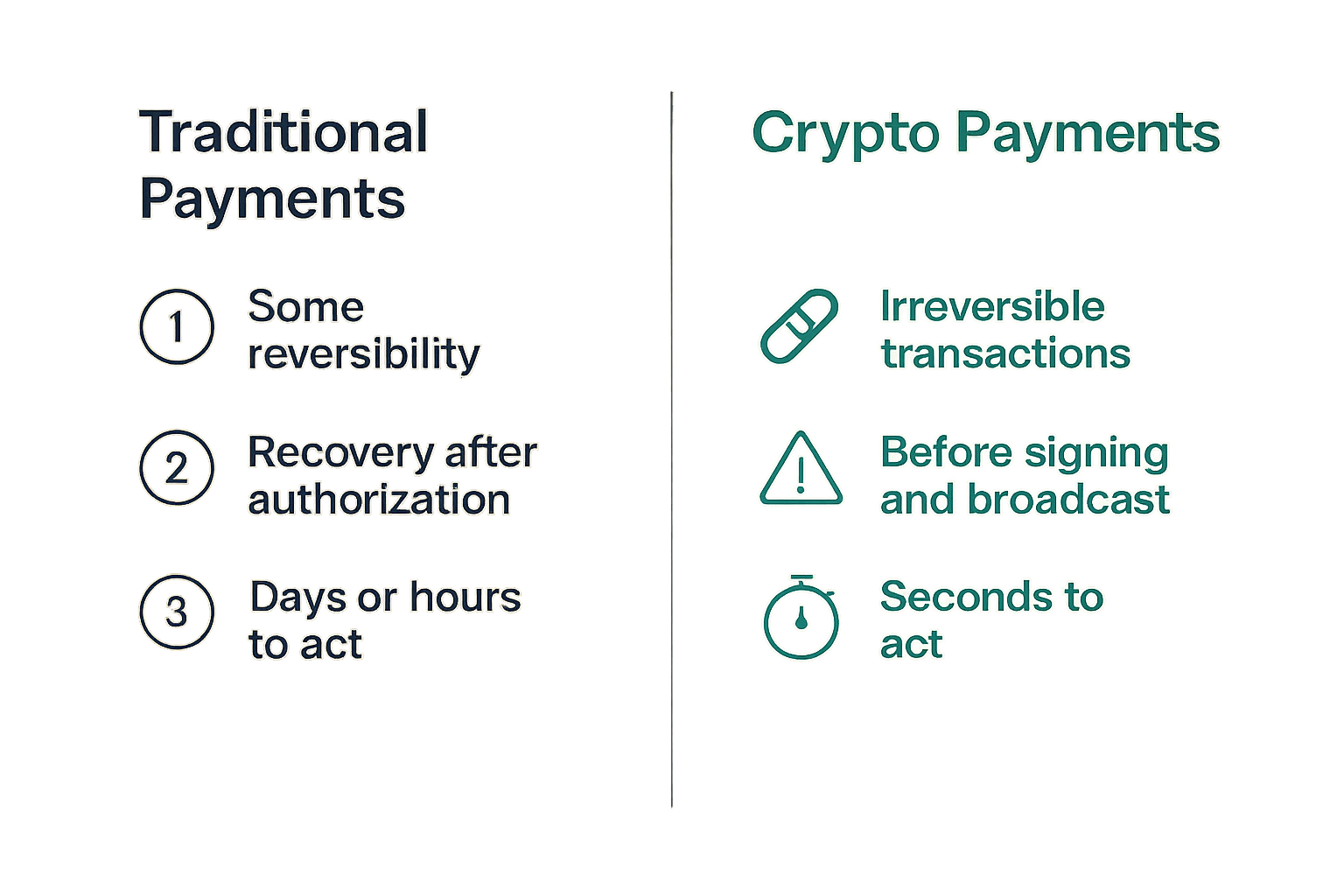
Traditional payment fraud tooling assumes some reversibility. A card network can claw back a transaction. A bank can freeze an account. The threat model is adversarial, but there's a recovery path.
Crypto removes that safety net almost entirely. Once a transaction is confirmed on-chain, the funds belong to whoever controls the receiving keys. There is no dispute resolution layer, no acquirer to call, no ACH return window. The entire risk surface compresses into the seconds before broadcast.
No chargebacks, no reversals
The practical consequence is that your threat intelligence needs to fire before the transaction is signed and broadcast — not as a post-hoc audit. In card payments, fraud detection can be a background process because you have days or hours to reverse a bad authorization. In crypto, your window is the pre-confirmation UX flow. Miss it there, and you're writing an incident report.
This is why so many crypto payment teams end up with compliance tooling that doesn't actually protect them. They adopt tools designed for the post-transaction audit use case and plug them into a checkout flow that has already moved funds. The detection is real. The intervention window is gone.
On-chain data is public but noisy
The paradox of blockchain transparency is that you have more raw data than almost any other payment environment, and most of it is operationally useless without enrichment. A raw transaction hash tells you almost nothing about whether the counterparty is a sanctioned entity, a mixer exit, a wallet associated with a known exploit, or a completely legitimate user who happens to use a privacy tool.
Enrichment — mapping addresses to entities, tracing fund flows, flagging known cluster behaviors — is where threat intelligence feeds earn their cost. But enrichment quality varies enormously across vendors and open-source datasets, and latency varies even more.
Practical rule: Treat on-chain transaction data as the signal substrate, not the intelligence itself. Raw blockchain data tells you what happened. Threat intelligence tells you what it means.
The four threat layers every crypto payment stack faces
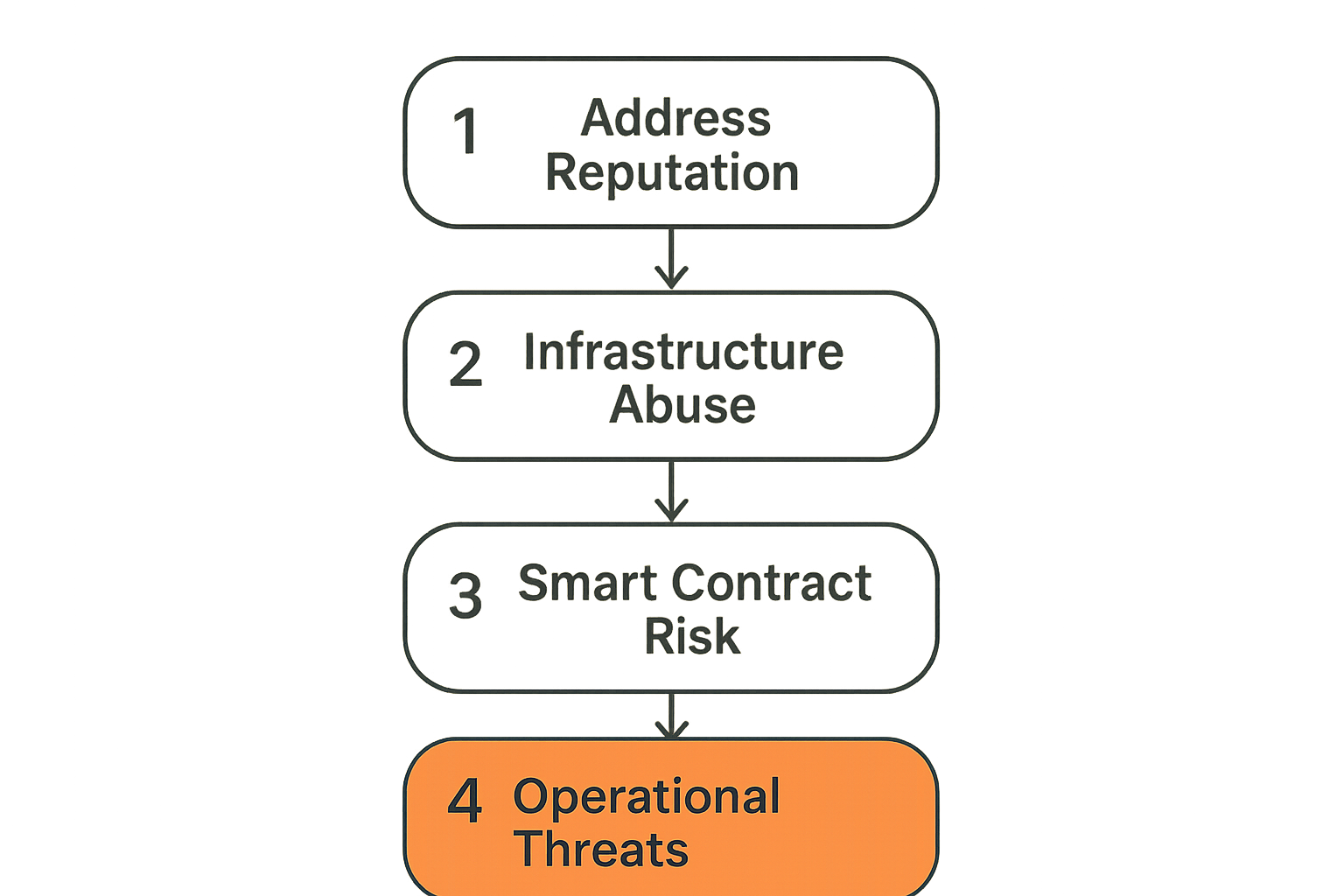
Before you can design a threat intelligence integration, you need a clear taxonomy of what you're defending against. Most teams collapse this into "fraud detection" and miss three other categories that generate real losses.
Address and entity reputation
This is the most obvious layer and the one most vendors cover. You're asking: is this wallet address associated with known bad activity? Sanctions lists (OFAC, EU, UN), exchange hacks, ransomware wallets, darknet markets, and mixer-adjacent clusters all generate address-level signals.
The challenge is that address reputation is time-sensitive and context-dependent. A wallet that was clean six months ago may be flagged today because of downstream fund movements it had nothing to do with. An address flagged as "mixer-adjacent" may belong to a privacy-conscious individual with no malicious intent. False positive rates in this category are high, and acting on every flag without a risk-scoring layer creates significant friction.
Infrastructure and API abuse
This layer is underweighted by most crypto payment teams. Your RPC nodes, webhook endpoints, signing infrastructure, and admin APIs are all attack surfaces. Infrastructure threat intelligence covers things like: this IP range is known to probe Web3 RPC endpoints; this pattern of requests matches a known front-running bot; this API key rotation pattern matches compromised credential reuse.
The team at threatcrush.com covers this class of threat in detail — it's the intersection of traditional SOC work and crypto-native attack patterns that most pure-play blockchain analytics vendors miss entirely.
Smart contract and protocol risk
If your payment stack interacts with DeFi protocols, wrapped token bridges, or third-party smart contracts, you inherit their risk surface. Protocol exploits, rug pulls, and bridge hacks have moved billions in the past few years. Threat intelligence here means monitoring for: new exploit disclosures against protocols you touch, anomalous liquidity movements that precede exploits, and governance attacks on protocols whose tokens you accept.
This category requires a different kind of feed — closer to vulnerability intelligence than address reputation — and most payment teams haven't wired it in at all.
Operational and social engineering threats
The softest layer to measure but consistently among the most damaging: targeted phishing of your engineering or finance team, fake support escalations, SIM-swap attacks on team members with key access, and impersonation of your platform toward users. These generate real payment losses but don't show up in on-chain analytics at all.
Operational threat intelligence here overlaps with traditional corporate security: dark web monitoring for leaked credentials, mention tracking for your brand in attacker forums, and anomaly detection on access patterns to your signing and custody systems.
Mapping threat signals to the payment lifecycle
The practical question is not "what threats exist" but "when do I check, and what do I do when a signal fires." Threat intelligence is only useful when it's wired to a decision point with a defined response.
Pre-authorization screening
This is the critical window. Before you generate a payment address, before you display a QR code or invoice, screen the counterparty address if you know it. For send flows (you're paying out), this is straightforward — you know the destination before you sign. For receive flows (user is paying you), you often don't know the sending address until a transaction is detected in the mempool.
A useful pattern for receive flows: generate a single-use deposit address per transaction, monitor the mempool for incoming transactions to that address, and run an async screen before your backend marks the payment as accepted. This gives you a few seconds of reaction time even on receive flows.
PRE-AUTH SCREENING SEQUENCE:
1. User initiates payment intent
2. Generate single-use deposit address
3. Return address + payment URI to frontend
4. Subscribe to mempool events for that address
5. On mempool detection: async screen sending address
6. If flagged HIGH risk: hold confirmation, alert ops team
7. If flagged MEDIUM: log, continue, add to review queue
8. If clean: mark payment as pending, wait for confirmation
In-flight monitoring
In-flight means between mempool detection and on-chain confirmation. This window is short (seconds to minutes depending on network and fee environment) but not zero. You can use it to catch transactions that passed pre-auth screening but trigger real-time signals — a fund flow tracer that identifies the sending address as a recent mixer output, for example, or a protocol-level anomaly on a bridge transaction.
In practice, most teams can't hard-block a transaction that's already in the mempool — it's going to confirm regardless. What you can do is flag it for manual review before releasing goods, before triggering downstream settlement, or before crediting a user's internal balance.
Post-settlement enrichment
Post-settlement intelligence is not a fallback for failed pre-auth — it's a different and complementary function. It's where you build the audit trail, update your risk models, surface patterns across transactions, and generate the reporting your compliance team needs. It's also where you catch slow-moving threats: a cluster of transactions that individually scored clean but collectively trace back to a single suspicious entity.
Practical rule: Pre-auth screening protects individual transactions. Post-settlement enrichment protects your platform over time. You need both, and they have different latency and storage requirements.
Choosing and integrating threat intelligence feeds
On-chain versus off-chain feeds
The feed landscape breaks down along two axes: on-chain (derived from transaction graph analysis, address clustering, fund flow tracing) and off-chain (sanctions databases, dark web scrapes, known attacker infrastructure, leaked credentials).
| Feed type | Latency | Coverage | Integration complexity | False positive rate |
|---|---|---|---|---|
| On-chain address reputation | Minutes to hours | High for known clusters | REST API, webhook | Medium-high |
| Sanctions / watchlist | Near real-time | Regulated entities only | REST API, batch sync | Low |
| Infrastructure / IP threat | Real-time | Network layer threats | Middleware, API | Medium |
| Protocol exploit intelligence | Hours to days | DeFi / bridge protocols | RSS, webhook, API | Low |
| Dark web / credential monitoring | Hours | Operational threats | Managed service | Low |
For most crypto payment stacks, you need at minimum: a sanctions feed, an on-chain address reputation feed, and some form of infrastructure threat signal at your API gateway layer. Protocol exploit intel is important if you route through DeFi. Dark web monitoring is important once you're operating at scale with meaningful key holders.
Feed quality and latency requirements
The mistake teams make is benchmarking feeds on coverage alone. Coverage (what percentage of known bad addresses does the feed flag) matters, but latency and update frequency matter more for runtime screening. A feed that catches 95% of known bad addresses but updates hourly is dangerous for a payment stack processing in near real-time — the gap between an exploit happening and the feed reflecting it is exactly the window attackers exploit.
When evaluating feeds for production integration, ask: what is the p95 latency for a new event to appear in the feed after on-chain confirmation? What is your SLA for sanctions list updates? What is the webhook delivery reliability and retry policy?
Operationalizing signals: rules, thresholds, and automation
Raw signals don't make decisions. Rules do. This is the layer where most threat intelligence integrations break down — teams get the feed working and then build a binary block/allow rule that either blocks too aggressively (killing conversion) or too loosely (missing real threats).
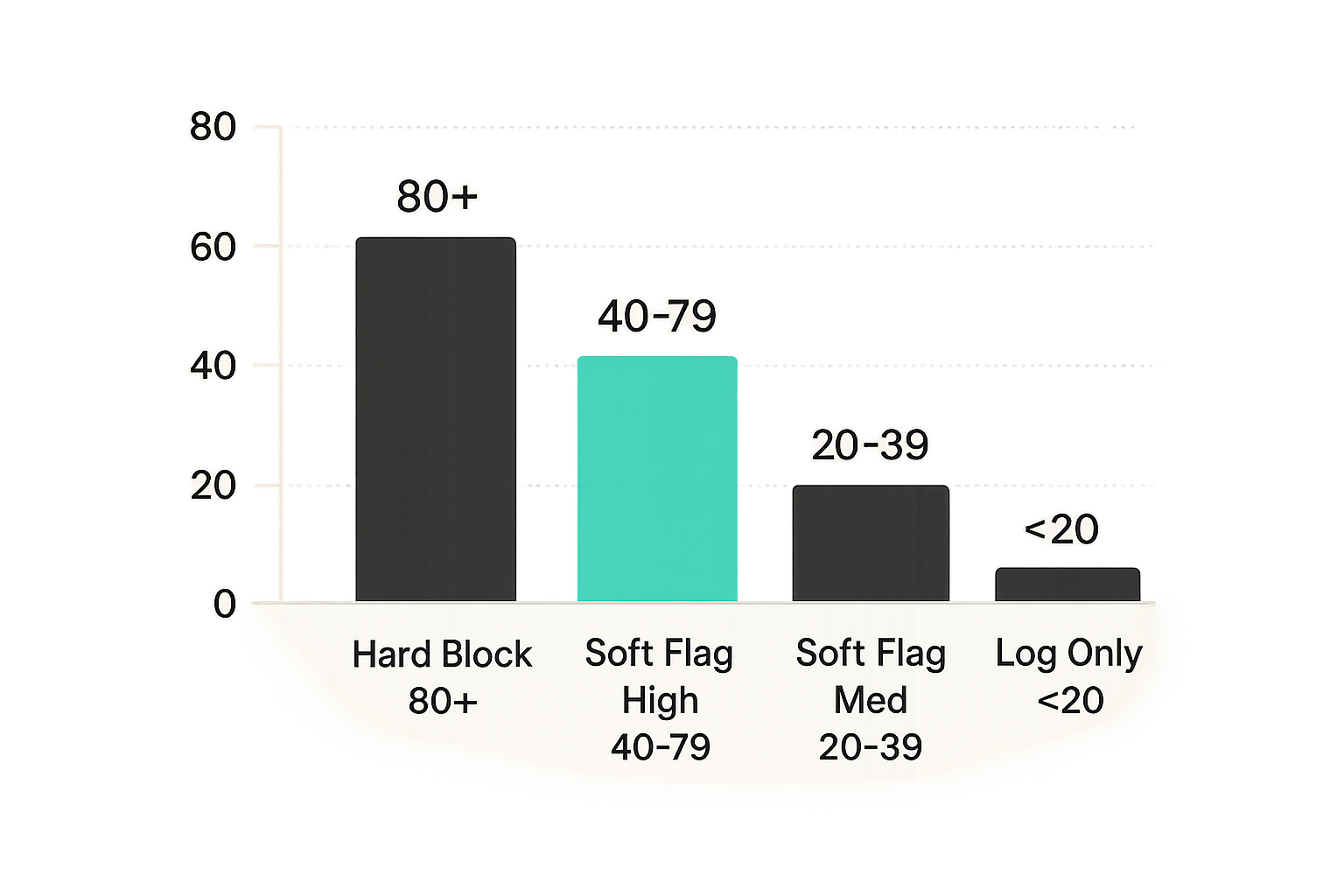
Hard blocks versus soft flags
A useful way to think about it is: hard blocks are for categorical compliance failures (OFAC hit, UN Security Council designation), and soft flags are for probabilistic risk signals (mixer-adjacent, high-risk jurisdiction, unusual transaction pattern). These require different response actions and different operational ownership.
| Signal type | Example | Recommended action | Owner |
|---|---|---|---|
| Hard block | Sanctioned entity match | Reject transaction, log, notify compliance | Automated + compliance team |
| Hard block | Known ransomware wallet | Reject, freeze account, alert ops | Automated + security team |
| Soft flag - high | Mixer output, recent exploit | Hold for manual review, delay settlement | Ops review queue |
| Soft flag - medium | High-risk cluster, unusual amount | Log, continue, flag for post-settlement review | Analytics |
| Soft flag - low | First-time counterparty, novel address | Log only | Analytics |
The practical question is: who owns the review queue for soft flags, and what is the SLA for clearing holds? If you build a system that flags 8% of transactions as medium-risk and routes them to manual review, you need staffing and tooling to clear that queue within your settlement window. Many teams build the flagging logic and not the review workflow, and end up with a backlog that defeats the purpose.
Building a scoring model you can tune
A binary block/allow rule based on a single feed is fragile. A scoring model that aggregates signals from multiple feeds, weights them by reliability and recency, and produces a numeric risk score is more operationally useful and more tunable.
A minimal scoring approach:
- Assign base scores per signal source (e.g., OFAC match = 100, mixer-adjacent = 40, high-risk jurisdiction = 20, novel address = 10)
- Weight by recency (signals older than 30 days decay by 50%)
- Weight by feed reliability score (track your feed's false positive rate over time)
- Sum and normalize to 0–100
- Define thresholds: 80+ = hard block, 40–79 = soft flag high, 20–39 = soft flag medium, below 20 = log only
- Review threshold calibration monthly against confirmed outcomes
This approach lets you tune aggressiveness without rebuilding your integration, and it gives compliance teams a defensible paper trail.
Practical rule: Build your scoring model to be auditable first. The ability to explain exactly why a specific transaction was flagged — which feeds, which signals, what scores — is as important as the block decision itself.
Common failure modes when teams build this wrong
Screening only at checkout
This is the single most common failure. Teams add address screening to the checkout UI — the user inputs their wallet, a call goes out to a screening API, a green check appears — and consider the job done. This misses: transactions that route through intermediate addresses, payments that split across multiple sends, and the entire infrastructure threat layer.
Checkout-only screening also creates a false sense of coverage that discourages building the deeper integration. If your dashboard shows "100% of transactions screened," but your definition of screened is a single point-in-time address check at the checkout step, you have a coverage illusion.
Treating feeds as fire-and-forget
Third-party threat feeds are not infrastructure in the way your RPC node or database is. They change schema, they deprecate endpoints, they have data quality regressions, and they occasionally go down. Teams that integrate a feed, verify it works at launch, and never monitor it again tend to discover the problem when they're asked during an incident why flagged addresses weren't caught.
What breaks in practice is: the feed's API changes a field name, your parser silently fails, every request returns an empty risk array, and your scoring model defaults to clean. Meanwhile, transactions are going through unscreened.
Feed health monitoring — testing with known-bad seed addresses on a regular schedule, alerting on unexpected response changes, tracking hit rate anomalies — is not optional.
What breaks under load and adversarial conditions
Rate limits and fallback logic
Threat intelligence APIs are not infinitely scalable on your behalf. Every major feed vendor has rate limits, and those limits often become visible for the first time during a traffic spike — which is exactly when you least want degraded screening.
You need a defined fallback policy: if the screening API returns a timeout or 429, do you fail open (allow the transaction and log for review) or fail closed (hold the transaction until you can screen)? The right answer depends on your business model and risk tolerance, but many teams have no explicit policy and inherit whatever the code defaulted to when someone hit an unhandled exception.
A practical implementation: cache screening results for known addresses (with a short TTL — 5–15 minutes for active transactions), implement exponential backoff with a local risk-estimation fallback for new addresses, and route all fallback-triggered transactions to a review queue rather than silently allowing them.
Feed staleness during incident spikes
A large exploit or hack generates a wave of new address flags in the minutes and hours following discovery. This is also when your payment volume may spike as users rush to move funds. The intersection — high screening demand, high feed update frequency — creates a staleness problem: your cached data is stale, your feed is hammered, and transactions that should be flagged are passing through on cached clean results.
The operational response is to have a manual override channel: a way to push a high-priority address flag directly into your local screening layer without going through the external feed. This is essentially your own internal threat feed, and it's what security-mature teams use to respond to incidents faster than any vendor feed can.
Integration patterns: APIs, webhooks, and event pipelines
Synchronous versus asynchronous screening
Synchronous screening — a blocking API call in the payment request path — gives you the cleanest user experience (no payment proceeds until screening completes) but adds latency to every transaction and creates a single point of failure. For most checkout flows, a 200–500ms screening call is acceptable if the vendor SLA is solid. Beyond 800ms, you'll see measurable conversion drop.
Asynchronous screening — submitting the address for screening and receiving a callback or polling for results — decouples the checkout UX from the screening latency but requires you to hold payment in a pending state and handle the callback reliably. This is more complex to build but scales better and degrades more gracefully when the feed is slow.
For high-volume payment infrastructure, the practical pattern is: synchronous screening for the initial checkout address check (blocking, but fast), asynchronous screening for mempool-detected sending addresses (non-blocking, triggered by event), and batch asynchronous for post-settlement enrichment.
Webhook-driven threat updates
Several feed vendors offer outbound webhooks that push new flags to your system rather than requiring you to poll. This is architecturally preferable for operational threat intelligence — you want to know within minutes if an address you have in an active payment session just got flagged, not find out on your next polling cycle.
Webhook integrations require the same operational care as any inbound webhook: idempotency keys, signature verification, retry handling, and a dead-letter queue for failed deliveries. A threat update that never arrives because your webhook handler was down during a maintenance window is not a theoretical failure mode.
WEBHOOK INTEGRATION CHECKLIST:
- Verify HMAC signature on every inbound event
- Idempotency: deduplicate by event_id before processing
- Process in async worker, return 200 immediately to sender
- Dead-letter queue for processing failures
- Alert on dead-letter queue depth > N
- Test with known-bad seed events weekly
Connecting proactive and reactive security work
The teams that do this well treat threat intelligence as a shared data layer between their payment engineering team and their security function — not a separate compliance tool that sits outside the main stack.
Closing the loop with incident response
When a real incident occurs — a flagged transaction that slipped through, an infrastructure probe that preceded an exploit, a compromised team member's credentials — the after-action process needs to feed back into the screening layer. What signals were available that the system missed? Was it a feed latency issue, a scoring threshold problem, or a coverage gap?
Without a structured feedback loop, threat intelligence integrations drift. They were calibrated for the threat landscape at build time and become progressively less effective as attack patterns evolve. The review cadence should be: threshold calibration monthly, feed coverage audit quarterly, full integration review after any confirmed incident.
That changes the conversation from "do we have threat intelligence" to "how well is our threat intelligence actually working" — which is the right question for a production payment platform.
Product fit: where coinpayportal.com fits this architecture
Building the threat intelligence layer described above from scratch is significant engineering work: feed integrations, scoring models, webhook pipelines, fallback logic, review queues. The alternative is starting with payment infrastructure that already has these layers built in and configurable.
CoinPayPortal is built for developers and merchants who need production-grade crypto payment infrastructure without assembling every piece from scratch. The practical relevance to threat intelligence architecture is this: when your payment gateway already handles address screening, transaction monitoring, and webhook-driven alerting at the infrastructure layer, your engineering work shifts from building the pipeline to configuring the thresholds and owning the business logic. That's the right division of labor for most teams — you understand your risk tolerance and your user base; the platform handles the feed integrations and the operational reliability of the screening layer.
If you're evaluating payment infrastructure and threat intelligence tooling in parallel, the question to ask is: at which layer does the platform's responsibility end and yours begin? A well-architected platform makes that boundary explicit and gives you hooks (webhooks, APIs, configurable rule sets) to extend it.
Try coinpayportal.com
CoinPayPortal gives developers and merchants a complete crypto payment gateway with built-in transaction monitoring, multi-chain support, and configurable screening hooks — so you can ship production payment infrastructure without rebuilding the security layer from zero. Start building at coinpayportal.com.
Try CoinPay
Non-custodial crypto payments — multi-chain, Lightning-ready, and fast to integrate.
Get started →