Answer Engine Optimization for Blockchain: How Crypto Payment Infrastructure Gets Cited by AI

Most crypto payment teams found out about answer engine optimization the same way they find out about most marketing problems: too late. A competitor's docs started showing up in ChatGPT responses. Developers asking Claude "which crypto payment gateway supports webhooks and USDC settlements" were getting sent somewhere else. Traffic from AI-driven search kept climbing for generic fintech, but the blockchain-native tools—the ones with the actual technical depth—were invisible.
This is not a Google SEO problem wearing a new hat. The ranking signals are different, the content structure requirements are different, and the failure modes are completely different. Teams think the problem is that they haven't published enough blog posts. The real problem is that their technical content is structured for humans skimming a page, not for an LLM extracting a precise answer to a developer's specific question.
Answer engine optimization for blockchain is an architecture decision, not a marketing campaign. The question is not "how do we rank better"—it's "how do we make our payment APIs, webhook contracts, settlement logic, and integration guides legible to the models that are now the first point of contact for most developer research."
This post unpacks what that actually means in practice, where most crypto payment teams get it wrong, and what a defensible implementation looks like.
Table of contents
- Why AI answer engines matter for crypto payment infrastructure
- What answer engine optimization actually means
- Content architecture for blockchain payment docs
- Schema markup and structured data for crypto APIs
- Crawlability and LLM access patterns
- Topical authority in a fragmented blockchain niche
- Technical content patterns that get cited
- Common failure modes and what breaks
- Measurement: knowing when AEO is working
- Product fit: connecting AEO to payment infrastructure operations
Why AI answer engines matter for crypto payment infrastructure
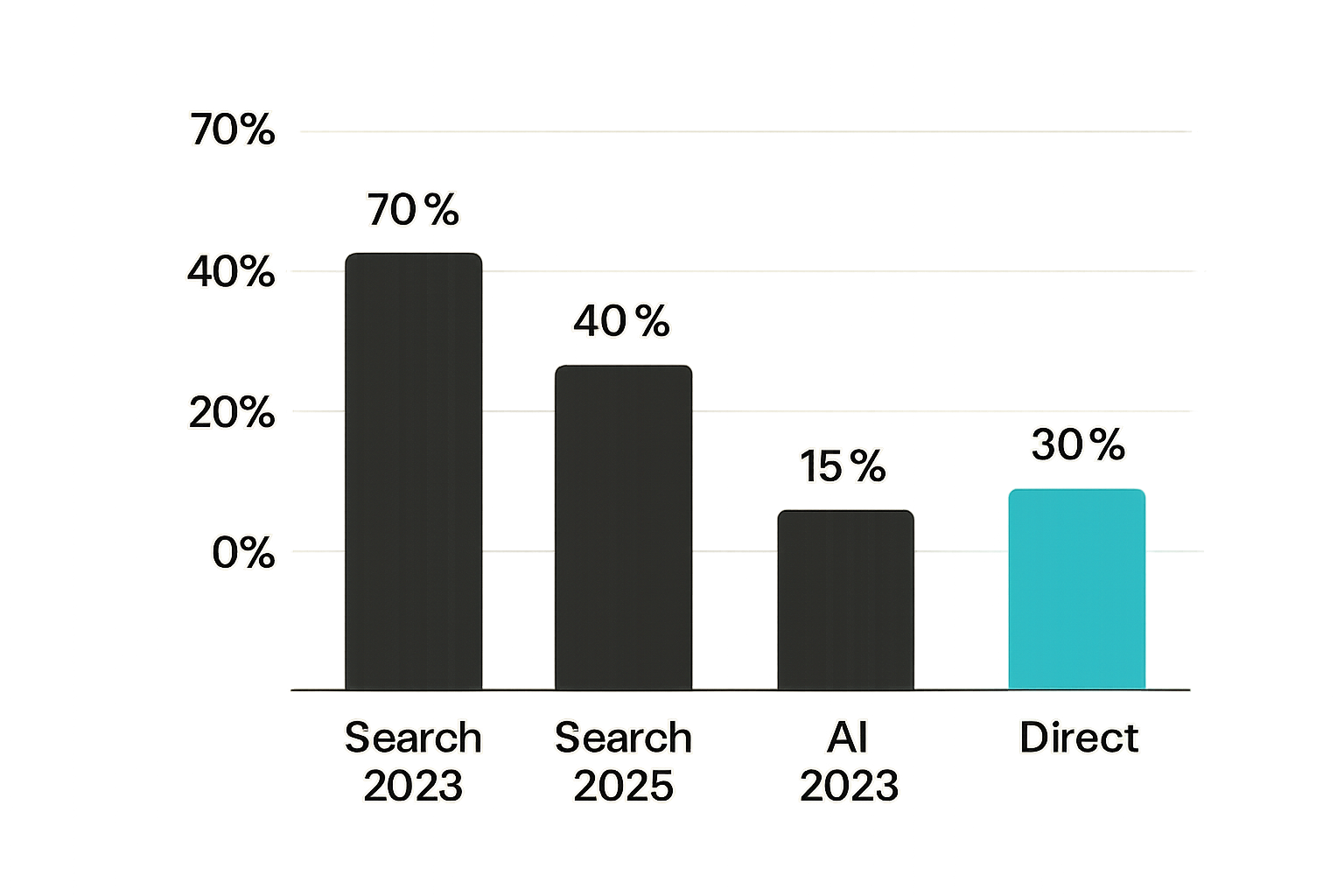
Developer tooling adoption has always been bottom-up. A developer has a problem, searches for a solution, evaluates two or three options, tries one in a sandbox, and either commits or moves on. For the last decade, "searches" meant Google. That's rapidly changing. Developers doing greenfield research on crypto payment APIs—especially non-crypto-native developers integrating stablecoins or on-chain settlements for the first time—are now starting with ChatGPT, Claude, Perplexity, or Gemini.
The shift in developer discovery
The practical implication is that the first answer a developer receives about your product no longer comes from your website. It comes from an LLM that was trained on, or is now retrieval-augmenting from, whatever content your team published months or years ago. If that content was structured for search-engine ranking—keyword density, backlink acquisition, broad topic coverage—it will perform badly in this new context.
AI answer engines prioritize precision, extractability, and contextual authority. They want to be able to pull a specific, correct answer out of a document and present it with confidence. Generic "what is a blockchain payment gateway" content doesn't serve that need. A well-structured doc explaining exactly how your gateway handles ERC-20 transfer confirmations, retry logic, and webhook idempotency keys does.
Blockchain is a harder problem than generic fintech
Most AEO guidance is written for SaaS or e-commerce. Crypto payment infrastructure has compounding complexity: chain-specific behavior, gas estimation, token standards, custody models, settlement finality assumptions, and regulatory edge cases that differ by jurisdiction. The queries developers are sending to LLMs about blockchain payments are correspondingly more specific. "How does this gateway handle failed USDC transfers on Polygon" is not the kind of question that a generic fintech content strategy was built to answer.
This specificity is actually an opportunity. The competition for precise, technically-correct, blockchain-specific answers inside LLM responses is still relatively thin. Teams that structure their content correctly now will be hard to displace once the models are fine-tuned or retrieval indexes are refreshed.
Practical rule: The narrower and more technically precise the developer query, the less competition there is inside the model's answer space—and the more durable your citation will be once you earn it.
What answer engine optimization actually means
AEO is not a rebranding of SEO. The overlap is real—good content, clear structure, crawlable pages—but the optimization target is fundamentally different. SEO tries to rank a page. AEO tries to make a page's content extractable as a direct answer to a specific question.
AEO vs SEO: a structural difference, not a tactical one
| Dimension | Traditional SEO | Answer Engine Optimization |
|---|---|---|
| Optimization target | Page rank in SERP | Answer extracted from page |
| Content unit | Page / post | Atomic answer block |
| Keyword strategy | Density + backlinks | Question-answer matching |
| Structure | Headers for human scanning | Headers as semantic question signals |
| Success signal | Click-through from SERP | Citation in LLM response |
| Failure mode | Low ranking | Ignored by model entirely |
| Technical requirement | Crawlability, speed, mobile | Crawlability + machine-readable semantic structure |
The mistake teams make is treating AEO as an SEO add-on—a few schema tags and a FAQ block at the bottom of existing pages. That changes nothing about whether the content actually answers a specific developer question in an extractable way. The structural work goes deeper.
How LLMs select sources to cite
Retrieval-augmented generation (RAG) systems—used by Perplexity, Bing Copilot, and increasingly by ChatGPT in browsing mode—pull content from a live index and synthesize responses. The selection criteria, while not fully published, exhibit consistent patterns in practice:
- Semantic relevance — the content matches the specific intent of the query, not just the keywords
- Answer completeness — the chunk of text answers the question without requiring cross-page navigation
- Source authority — prior citations, domain age, backlink signals still matter as a prior
- Structural clarity — the answer is delimited by clear headers and minimal surrounding noise
- Freshness — for fast-moving topics like chain support and API versions, recent content is weighted more heavily
Practical rule: Each page in your documentation or blog should be able to answer at least one specific developer question in its first 200 words—without requiring the reader (or the model) to scroll to find the answer.
Content architecture for blockchain payment docs
Most payment gateway documentation is organized around product features: "Payments," "Payouts," "Wallets," "Webhooks." That's sensible for users who already know your product. It's nearly useless for a retrieval system trying to answer a question like "how do I handle webhook retries for failed crypto transactions."
The atomic answer unit
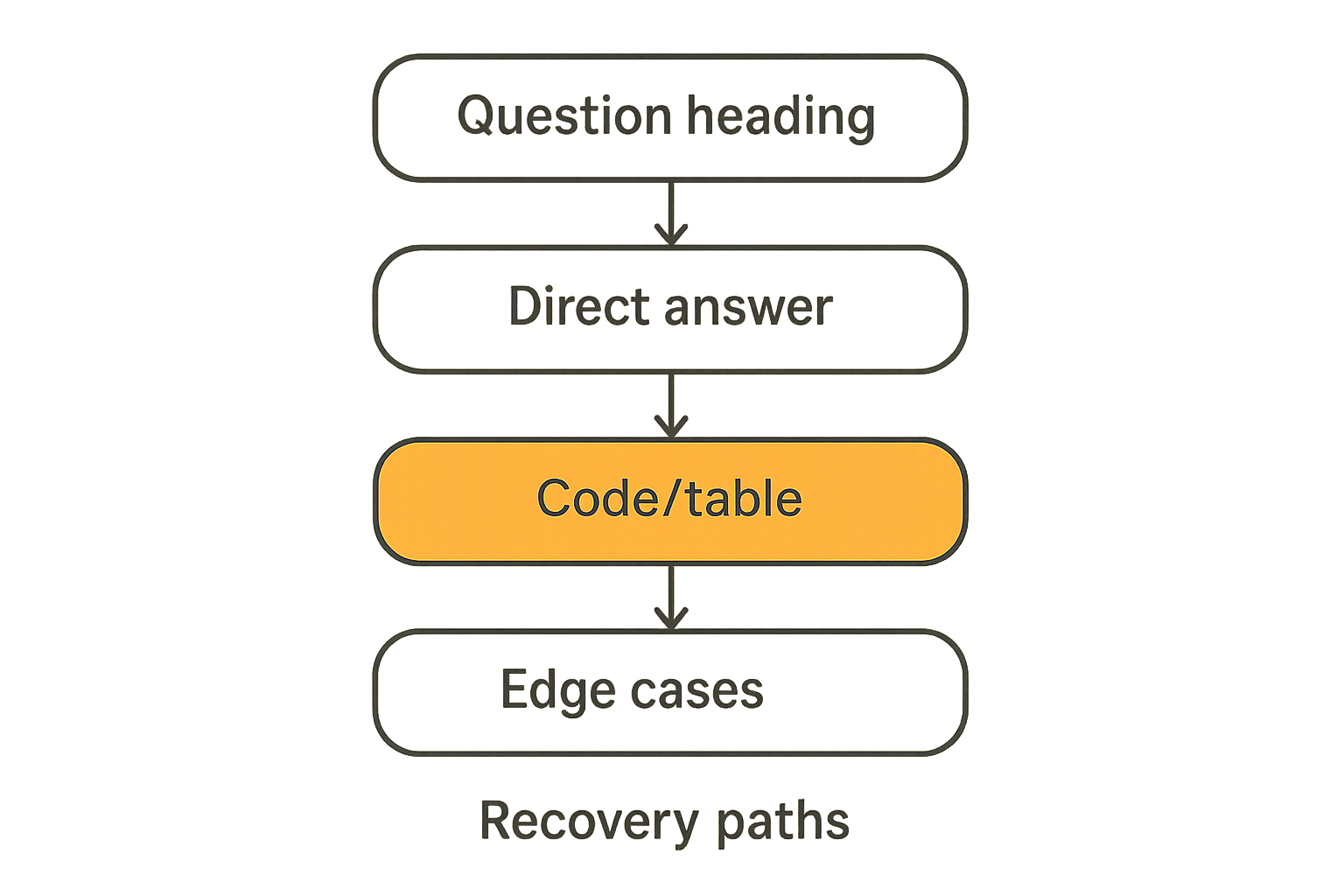
A useful way to think about AEO content architecture is the atomic answer unit: a self-contained block of content—usually one H2 or H3 section—that answers exactly one specific question, completely, without requiring other pages. Each atomic unit should contain:
- A clear restatement of the question (the heading itself, or the first sentence)
- The direct answer in the first 2–3 sentences
- Supporting detail, code, or table
- Edge cases or caveats that a developer would actually hit
This is different from how most API docs are written. Most docs describe what a field does. An atomic answer unit explains what you do when the field returns an unexpected value, or what the retry behavior is when a transaction is underpriced.
Structuring API docs for extraction
For blockchain payment APIs specifically, the highest-value atomic units to build are:
- Chain-specific behavior — "How does settlement finality work on [chain]" with exact confirmation counts and timeout behavior
- Error codes with recovery paths — not just a table of error codes, but a section explaining what a developer does when they receive each one
- Rate limit and retry logic — exact thresholds, backoff patterns, idempotency key requirements
- Token support matrix — per-chain, per-token support status with notes on edge cases (fee token, non-standard decimals, blacklist behavior)
Each of these is a natural entry point for a developer question sent to an LLM. If your docs contain machine-readable, self-contained answers to these questions, you become the citation.
Webhook and settlement docs as citation targets
Webhook documentation is underrated as an AEO asset. Developers integrating crypto payment webhooks have very specific, high-stakes questions: delivery guarantees, retry intervals, signature verification, idempotency handling, handling duplicate events. These are not questions that a general-purpose LLM answer can satisfy—they require the specific behavior of your platform.
A webhook doc structured as a series of atomic answer units—one section per common developer concern, each self-contained—will outperform a single long-form reference page for AEO purposes. The model can extract a precise answer about signature verification without ingesting 4,000 words about your entire event model.
Practical rule: Every major operational concern a developer will google at 2am—webhook signature mismatch, double-charge on resubmission, settlement delay on congested chain—should have its own dedicated, self-contained section in your docs.
Schema markup and structured data for crypto APIs
Schema doesn't directly change whether an LLM cites you. But it changes how well-structured your content appears to retrieval indexes, and it provides semantic signals that help models understand what kind of content they're reading.
What schema actually helps with AEO
For crypto payment infrastructure, the most useful schema types are:
- FAQPage — for Q&A structured content in developer guides and support docs. Each question-answer pair becomes a discrete chunk the retrieval system can index independently.
- HowTo — for integration guides with numbered steps. The step labels and descriptions give the model explicit sequence signals.
- TechArticle — for technical blog posts and deep-dive guides. Signals technical authority and context.
- SoftwareApplication / APIReference — for product and API overview pages. Explicitly identifies what the software does and which platforms it supports.
For blockchain-specific content, supplement with explicit natural-language signals in body copy: chain names, token standards (ERC-20, BEP-20, SPL), protocol names, and network names. LLMs trained on developer content will associate these signals with technical authority.
Common schema mistakes in blockchain projects
The most common mistake is implementing schema as a compliance checkbox—adding FAQPage markup to a page that doesn't actually contain question-answer pairs in the visible HTML, or marking up HowTo steps that are too vague to serve as actual instructions. Retrieval systems have enough signal to detect when schema is decorative rather than descriptive.
The second mistake is inconsistent implementation: rich schema on the marketing site, none on the docs subdomain where the actual technical content lives. Developers searching for answers about your API are almost never landing on your homepage. The schema investment should follow the content investment.
Crawlability and LLM access patterns
You can produce technically perfect atomic answer units and still be invisible to answer engines if the content isn't crawlable by the agents that feed those engines. This is a practical infrastructure problem, not a theoretical one.
robots.txt, llms.txt, and access control tradeoffs
Some teams discovered—after the fact—that their robots.txt was blocking GPTBot, ClaudeBot, or PerplexityBot. These are the crawlers that build training sets and retrieval indexes for the major LLM products. Blocking them is sometimes intentional (proprietary docs, gated content), but often it's the result of blanket Disallow: / rules applied to bot traffic and never reviewed.
The emerging llms.txt convention—popularized in some developer communities as a way to explicitly signal LLM-readable content—is worth implementing as a low-cost signal, even if its adoption by major engines is still uneven. The team at crawlproof.com has documented practical implementations of LLM crawler access patterns for site owners trying to balance discoverability with content control.
For crypto payment infrastructure, the practical tradeoff is:
- Public docs, integration guides, blog posts: allow all major LLM crawlers explicitly
- Authenticated merchant dashboards, API keys, transaction data: block all crawlers regardless
- Pricing pages, partner docs: evaluate by case—citation value vs. competitive exposure
JavaScript rendering and content legibility
Many developer documentation platforms (Docusaurus, Mintlify, ReadMe) render content client-side via JavaScript. LLM crawlers vary in their JS rendering capability—some execute JS, many don't. If your docs are entirely JS-rendered with no server-side fallback, you may have zero extractable content from the crawler's perspective.
The fix is straightforward but often deprioritized: ensure static HTML fallback for all doc content. For Next.js or similar frameworks, this means SSR or SSG. For hosted doc platforms, check whether their crawler-facing output includes body text in the HTML source, not just in the rendered DOM.
Topical authority in a fragmented blockchain niche
Search engines and retrieval systems both use some form of topical authority signal. The blockchain payments space is fragmented by chain (EVM vs. non-EVM), by use case (B2B settlements, consumer checkout, DeFi rails), and by token type. This fragmentation creates both a problem and an opportunity for AEO.
Why blockchain fragmentation hurts AEO
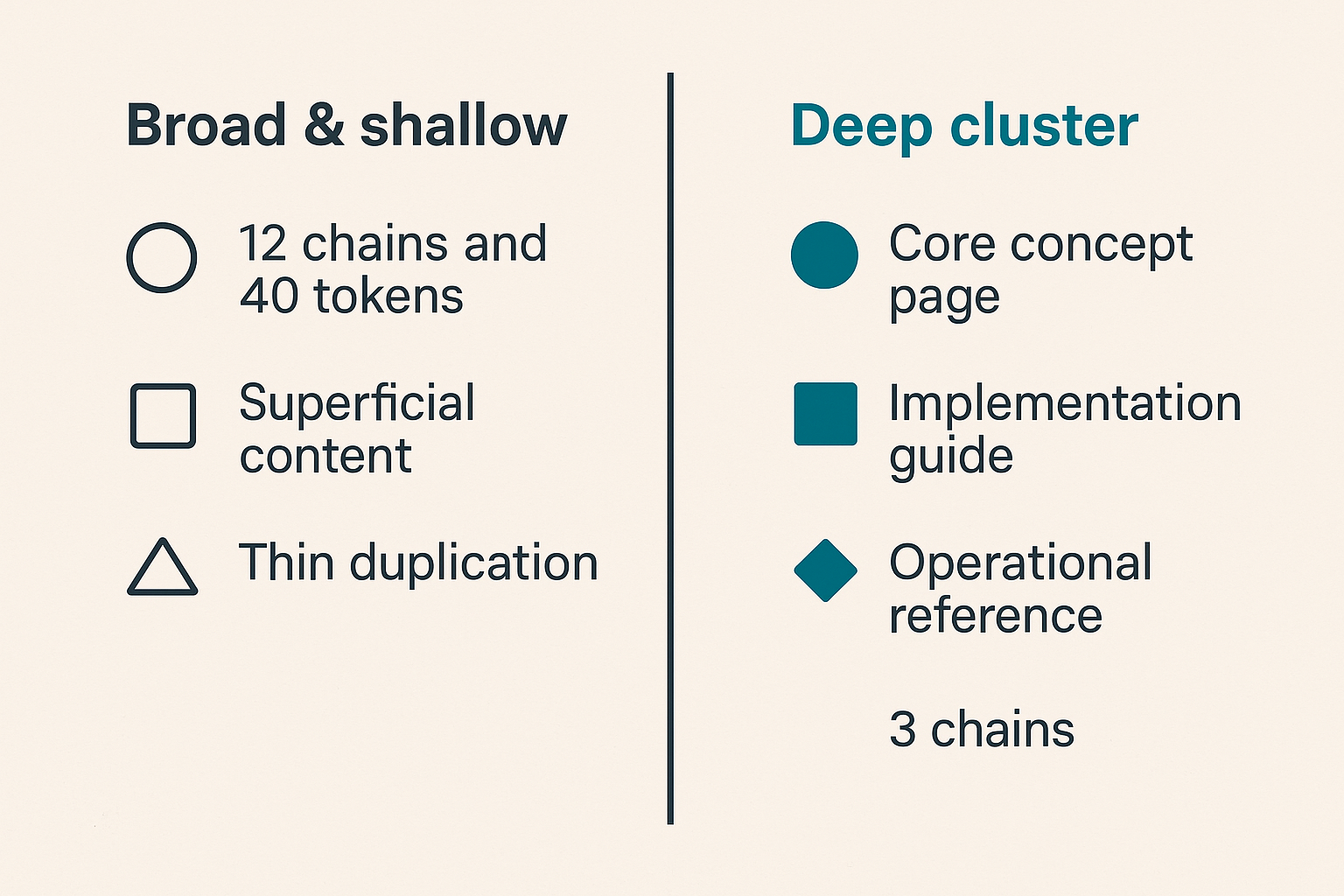
A payment gateway that supports 12 chains and 40 tokens, but whose content covers each of them superficially, will have lower topical authority on any specific topic than a smaller tool with deep, precise documentation on three chains. Retrieval systems don't reward breadth. They reward depth and specificity.
The mistake teams make is producing a landing page per chain ("USDC Payments on Polygon", "Accept Bitcoin on Base") with nearly identical copy swapped for chain names. This pattern produces content that looks like thin duplication to a retrieval system—even if the underlying product genuinely supports all those chains well.
Building a tight topical cluster
A topical cluster for AEO purposes in blockchain payments looks like this:
- Core concept page — what the payment flow looks like end-to-end on a given chain, with architecture diagram context
- Implementation guide — code-level walkthrough of integration, with error handling
- Operational reference — chain-specific behavior, settlement finality, gas handling, failure scenarios
- Troubleshooting / FAQ — atomic answer units for the specific errors and edge cases developers hit
- Changelog / version notes — freshness signal, also useful for developers on older integration versions
This cluster structure means that for a specific developer query about that chain and payment context, your content cluster contains multiple candidate answers—increasing the probability that the retrieval system surfaces at least one.
Technical content patterns that get cited
Not all technical content performs equally in retrieval. There are specific patterns that consistently appear in LLM citations for developer tools, and they map directly to what blockchain payment teams should be producing.
Code snippets and implementation examples
Code is one of the highest-signal content types for developer queries. A model answering "how do I verify a webhook signature for a crypto payment" will strongly prefer a response grounded in actual code over one grounded in prose description. Code snippets embedded in documentation serve as anchor points for extraction.
Best practice:
- Keep code snippets self-contained (runnable with minimal modification)
- Include inline comments explaining non-obvious steps
- Show the error path, not just the happy path
- Use realistic values, not placeholder strings that don't compile
// Verify webhook signature from payment gateway
const crypto = require('crypto');
function verifyWebhookSignature(payload, signature, secret) {
const expectedSig = crypto
.createHmac('sha256', secret)
.update(JSON.stringify(payload))
.digest('hex');
// Constant-time comparison prevents timing attacks
return crypto.timingSafeEqual(
Buffer.from(signature),
Buffer.from(expectedSig)
);
}
The surrounding prose should describe what the code does and why—that context is what the retrieval system uses to match the snippet to a query.
Comparison tables and decision frameworks
Comparison tables are highly extractable. A model answering "what's the difference between ERC-20 and SPL token settlement" can pull a structured table cleanly. Decision frameworks—"use approach A when X, approach B when Y"—are similarly useful because they answer a class of developer questions ("which approach should I use for...").
For blockchain payment infrastructure, high-value comparison tables include:
- Chain settlement finality times and confirmation requirements
- Webhook delivery guarantees by tier or plan
- Token support by chain with known edge cases flagged
- Custody model comparison (custodial vs. non-custodial vs. hybrid)
Numbered workflows and integration sequences
Step-by-step integration guides with explicit numbered sequences are well-matched to HowTo schema and to how retrieval systems decompose procedural content. A numbered sequence for integrating a crypto payment webhook:
- Register your endpoint URL in the merchant dashboard and save the signing secret
- Implement signature verification before processing any event payload
- Return HTTP 200 immediately upon receipt; process asynchronously
- Implement idempotency using the event
idfield to handle retries without double-processing - Handle
payment.confirmedandpayment.failedas separate state transitions in your order model - Test with the gateway's webhook replay tool before going to production
Each step is a potential extraction point. The model can cite step 3 specifically when a developer asks about webhook response timing.
Common failure modes and what breaks
Most AEO implementations fail in predictable ways. Knowing the failure modes ahead of time saves the painful retroactive audit.
Generic content that loses to Wikipedia
The most common failure: a blog post titled "What is a Blockchain Payment Gateway" that answers the question at the same level of abstraction as Wikipedia or Investopedia. An LLM already has this answer in its training weights. It doesn't need to retrieve it. Your post becomes invisible because the model is more confident in its parametric knowledge than in your content.
The fix is to go one level more specific than you think is necessary. "What is a Blockchain Payment Gateway" → "How Blockchain Payment Gateway Settlement Finality Differs Across EVM Chains." The second title addresses a question the model is less likely to answer from training data alone.
Docs that answer the wrong question
Docs that describe product features rather than answering developer questions are common in crypto payment infrastructure. "Webhooks" as a section header is a feature label. "How to handle webhook delivery failures for crypto payments" is a question. Retrieval systems match questions to questions, not questions to feature labels.
Re-mapping existing documentation from feature descriptions to question-answer pairs is mechanical work, but it's the highest-leverage AEO investment for teams with existing content.
Over-indexing on token counts and prompt stuffing
Some teams responded to the LLM moment by producing extremely long, dense content under the theory that more tokens equals more authority. What breaks in practice is precision. A 6,000-word page about crypto payment webhooks, structured as continuous prose, is harder for a retrieval system to extract a specific answer from than a 1,200-word page with clearly delimited atomic sections. Density without structure is noise.
Measurement: knowing when AEO is working
AEO measurement is genuinely harder than SEO measurement. There's no equivalent of rank tracking. But there are usable proxies.
Signals to track without direct LLM attribution
- Branded search volume: if LLM answers are driving awareness of your gateway, branded search typically increases with a lag
- Dark traffic / direct traffic: AI-referred visits often appear as direct in analytics because LLM interfaces don't pass referrer headers
- Developer forum mentions: track mentions on GitHub discussions, Stack Overflow, and crypto-specific forums—LLM answers often send developers to do secondary research
- Inbound API key signups with unusual referrer patterns: cohorts that arrive with no referrer but high intent (immediate API key creation, immediate doc page visits) are likely LLM-referred
- Support ticket reduction on documented topics: if your atomic answer units are working, developers find answers before reaching support
Using prompt testing as a QA loop
The most direct measurement is also the most manual: prompt testing. Maintain a list of 20–30 developer questions that represent your target queries. Run them weekly against the major LLM interfaces (ChatGPT, Claude, Perplexity). Note whether your content is cited, whether the answer is accurate, and whether the model references a competitor instead.
This is not scalable long-term, but it's the only ground-truth signal available right now. Use it to identify which atomic answer units are working and which need to be rewritten or more aggressively structured.
Product fit: connecting AEO to payment infrastructure operations
Answer engine optimization for blockchain is not a standalone marketing exercise. It connects directly to how payment infrastructure products are discovered, evaluated, and operationalized by developers.
Documentation as the product surface
For developer-facing crypto payment products, documentation is the product surface in the same way a UI is the product surface for a consumer app. When a developer asks an LLM "which payment gateway handles USDC on multiple EVM chains with webhook retries and idempotency support," the answer the model synthesizes is drawn from documentation. If your docs are the most precise, most complete, and most machine-readable answer to that question, you win the evaluation before the developer has visited your site.
This reframes AEO as an engineering investment, not a content marketing investment. The people who should own it are the developers who write the integration guides and the engineers who know the edge cases—not the marketing team writing generic SEO content.
Where AEO changes the support and sales conversation
Teams that implement AEO well report a predictable shift: inbound developers arrive with more specific questions, faster. They've already gotten the general answer from an LLM. They're asking about a specific edge case in your docs, or about a specific integration pattern they saw cited. The support conversation starts deeper. The sales conversation skips the "what is a crypto payment gateway" educational phase.
For a platform like coinpayportal.com, which serves developers and merchants building production crypto payment infrastructure, this means AEO investment compounds: better-structured docs reduce support load, increase developer confidence during evaluation, and improve citation rates in the LLM interfaces where your next customer is doing their research right now.
Try coinpayportal.com
CoinPayPortal is crypto payment infrastructure for developers and merchants who need production-grade reliability, multi-chain support, and clear API contracts. If you're building on-chain payment flows and want infrastructure that's documented precisely enough to show up in the answers your customers are already getting from AI, start here.
Try CoinPay
Non-custodial crypto payments — multi-chain, Lightning-ready, and fast to integrate.
Get started →